
With the rise of the web as a programming platform, a series of design patterns starting with MVC, MVVM and ranging to data binding, state store and GraphQL have been implemented in web applications. But what’s becoming a major tendency in app development is the data-centric approach of describing an application.
The application is the data
An application comes from a stored code which can be regarded as its starting configuration. The isles of programming code converted into an executable form may be viewed as immutable isles of data which are giving birth to the actual program. The variables and the allocated memory zones can be regarded as mutable isles of data that are visited and transformed by the signal which is the running app. Furthermore, an application may have a set of configuration data that is stored as a configuration tree that is also almost static compared to the running program.
Separating and structuring the mutable and the immutable data is the key to build a lasting solution that scales and adapts in time.
The application is the business
Separating the valuable data falls in the domain of architecture design of the current applications. For a web based app, that architecture is the client-server model with the division of the app in the UI, the server program, and the data centre. Usually, the data model used by the last part is carried over to the first two parts, which are structured more often with patterns of concern separation in mind, such as MVC or MVVM. But, as we will demonstrate below, the real application is the server processing part which can also be called the business logic. Also, the communication channel between client and server sections can be remote, local or direct, the last case depicting ‘classic’ apps like the desktop ones that will be greatly leveraged by the proposed architecture.
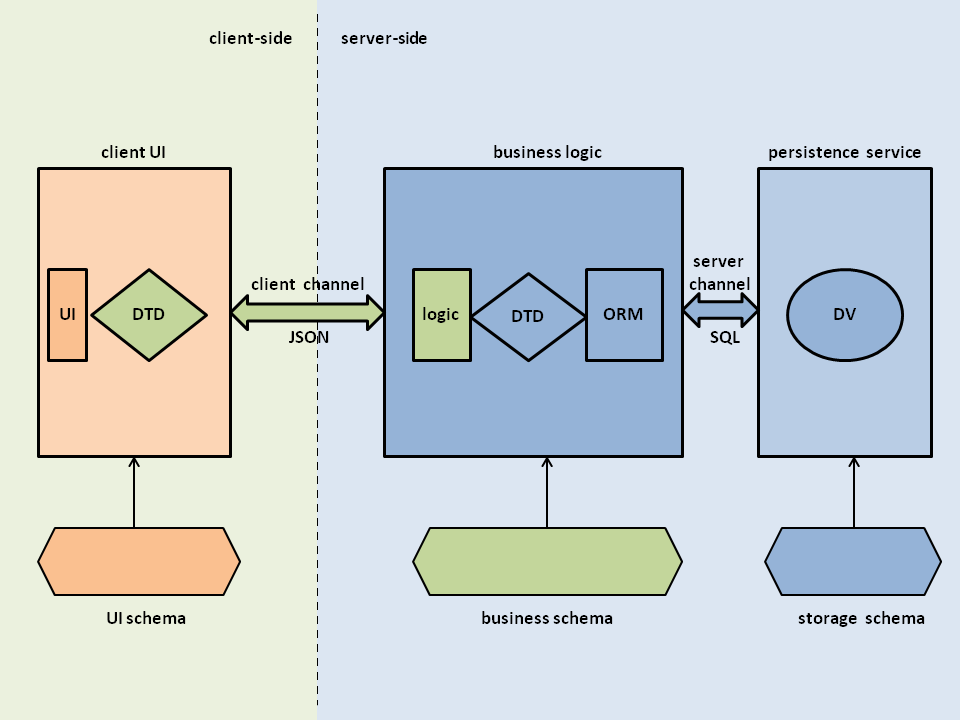
The 3 data models
Let’s assume that both data exchange channels from the UI to the business logic and from the business logic to the persistence service use JSON messaging. Each JSON message, either pulled or pushed, may have several kinds of data isles such as: content, validation, error, query params, and so on. This data structures can be tailored to correspond to the JSON schema describing the application data model, see e.g. the GraphQL approach. What if, immediately after receiving a message, or right before sending it we apply a data transformation over its data isles, something more complex and non-linear like a XSLT variant for JSON, or simpler and linear like the JUL Data Mapper.
We can now decouple the business logic model from the other two parts, the UI and the persistence layer, and can use three JSON schemas to describe each model separately.
It should be noted that an application can have multiple UI perspectives like web, mobile, desktop, ad version, paid version etc. it can also connect to several persistence services such as local or remote data base, cloud APIs, serverless etc. The advancement in versioning of the application’s data model is, in fact, the adjustment of its business logic model, and not necessarily of the other two parts which can have a quite different structure and field naming. If we regard the UI and the storage services of different perspectives as external services, it becomes clear that the application functionality should concentrate in its business logic part. This is now enabled by separating the three data models based on the data transformation applied on the JSON data channels. We will call the transformation code as a data transformation driver (DTD).
Workflow
First step is correctly identifying the business logic part of the app. This app part has certain common but not mandatory or exclusive features, such as: ability to serve multiple clients at the same time, residing server-side, externalization of the storage/persistence services. The key feature though, is processing the business critical data, process that includes automatic decision making, data validation, error handling, maintenance, data aggregation etc.
Second step is formatting all the requests and responses of each of the three parts of the application according to the usage and the semantics of the respective part, i.e. its data schema. As an example, if the client UI part sends a GET request to the server business logic, we usually send a query ID and a key/value hash of query parameters. We’ll use NAMED query params in the form ‘prop1.prop2.prop3 ‘, and convert the hash to a structured object that follows the UI data schema using a simple method like applying the JUL.ns() over each named key. The JSON response received from the server will have the items array, and maybe validation or error data structured to fit the data schema of the business logic, and not necessarily as direct members of the JSON root object.
Third step is determining where to insert the DTD code. For the UI client part, there is usually a remote JSON data channel to the business logic server endpoints like the REST API architecture. We’ll apply the DTD at the client endpoint of the data channel, just before calling JSON.stringify () or immediately after JSON.parse () nethods, or their equivalent hooks/callbacks.
The business logic is connected to a persistence/storage service via an ORM or an entity-to-service module and then, in many cases, a remote data channel that may not be JSON messaging. The ORM must be regarded as part of the data model of the service, and must follow the data schema of the persistence service. We will insert the DTD code as data transforming hooks on the argument values and on the response/result value of the CRUD and other ORM methods. For the cases where the exchange channel between the mid/second part of the app and the third part of the app is JSON, like web APIs or NoSQL, messaging, the DTD sits at the business logic endpoint of the data channel.
Fourth step is organizing the DTD code in modules. For the client UI, there is usually a single bidirectional DTD module that will be used to transform the sent or received JSON messages i.e. request and responses. At the business logic, there are usually multiple DTD modules, one for each persistence service, some of them acting only on the received JSON data. In special cases, when also user programmable processing is available at the persistence service, a DTD module may be applied at that end of the application.
Fifth step is end-to-end testing of the application with the inserted DTD modules. This is done by incrementally changing the structure of the data model of the business logic then adjusting the affected client UI and business-to-service DTD modules. The DTD code adjustment should be made via configuration, leaving intact the main data transformation code as in e.g. JUL Data Mapper. Of course, structural data changes may be applied also to the client UI or to the persistence services, albeit in a separate test step.
Types of DTD and related data channels
The DTD code can be scripted, run as a binary, or even embedded in hardware. All these methods have in common the running of the data transformation in memory, leaving as user configuration the DTD configuration matrix or its equivalent code. The in-memory data transformation can be applied over any tree-like data structures such as XML, DOM, SVG, JSON, etc. and is, essentially, language agnostic.
A common pattern of using data channels is transmitting over a physical infrastructure or delivering compressed/encrypted data in software. At a closer look, in all the cases when we have a data channel to transmit the relevant data, we also have at least one hardware or software data connector that acts on relevant data, in the simplest case as an identity matrix.
We will use the reverse of the before mentioned pattern as a rule for describing the architecture of a web app: in an application, wherever is a data connector i.e. a DTD, there is a data channel.
Summing up, the types of data channels in relation to a DTD are:
- Remote data channels: when the two ends of the data channel are on different systems/infrastructures
- Local data channels: when both ends of the data channel are on the same system
- Virtual/direct data channels: when we insert a data connector on an otherwise unaltered in-memory or direct data exchange
It’s worth mentioning that besides the typical one-to-one DTDs, there can also be one-to-many DTDs which may serve as a data aggregator for multiple data channels. In this case though, the problem of time syncing the data inputs will appear, changing the DTD from a direct linear matrix transformation into a state machine. You may want to use multiple one-to-one DTDs followed by a data aggregation module.
Applications
The typical scenario for applying the proposed architecture is the insertion of the DTDs in a client server web application. Given the clear distinction between the three parts of the app, the benefits of using the 3 data models are outlined previously, and apply to the deployed application, but especially to the phases of initial development, software maintenance, and software upgrading of the product.
The palette where a DTD can be applied is larger though, and includes mobile, desktop, embedded, VR or natural language ones, among others. This is because the UI/UX part of these types of applications can be regarded as a user perspective of accessing and manipulating the business part of the respective apps. For example, if we take a desktop app that connects to a local service database, the data bindings in the UI follow the naming and the structure of the database model through an ORM code. If, however, we insert a direct DTD before the ORM, not only we’ll be able to use a single UI code if we upgrade the connection to a production database, but we can use the business code that controls the CRUD operations for a different UI like e.g. a remote mobile app.
So, you see, the 3 data models is a straightforward way for you to build more scalable and more universal applications.







 The Zonebuilder
The Zonebuilder